Understanding MapReduce, from functional programming language to distributed system.
MapReduce is a computing model for processing big data with a parallel, distributed algorithm on a cluster.
It was invented by Google and largely used in the industry since 2004. Many applications are based on MapReduce such as distributed pattern-based searching, distributed sorting, web index system, etc.
MapReduce is inspired by the map and reduce functions, which commonly used in functional programming. Map and Reduce are not a new programming term, they are operators come from Lisp, which invented in 1956.
Let’s begin with these operators in a programming language, and then move on to MapReduce in distributed computing.
Map and reduce in Python
A funny pic shows the meaning of them:

Map
The map in the functional programming applies another function to a list, convert each element to another value, then finally returns a new list. We can use map to any data structure of sequence type, such as an array.
Suppose we want to multiple 2 to each element in a List, this could be finished in Python:
|
After run it with input, we will get another list:
|
Python has a builtin function map for this kind of task:
|
Reduce
Similarly, reduce applies a function to every two elements of a list, but it returns an aggregate result. It’s called fold in some programming languages.
|
We may implement it from scratch like this:
|
A programming model: MapReduce
Of course, the concept of MapReduce is much more complicated than the above two functions, even they are sharing some same core ideas.
MapReduce is a programming model and also a framework for processing big data set in distributed servers, running the various tasks in parallel.
It is a technology which invented to solve big data problems. Nowadays, the data volume is so huge that we can not solve it on one server.
The whole idea of MapReduce is a split-apply-combine strategy. We split the big data set into multiple parts and processing them parallelly on multiple servers, then combine the result with all outputs from servers.
Let’s make an analogy, we have a lot of ingredients, after the procedure of shredding and recombine, we make a lot of hamburgers.
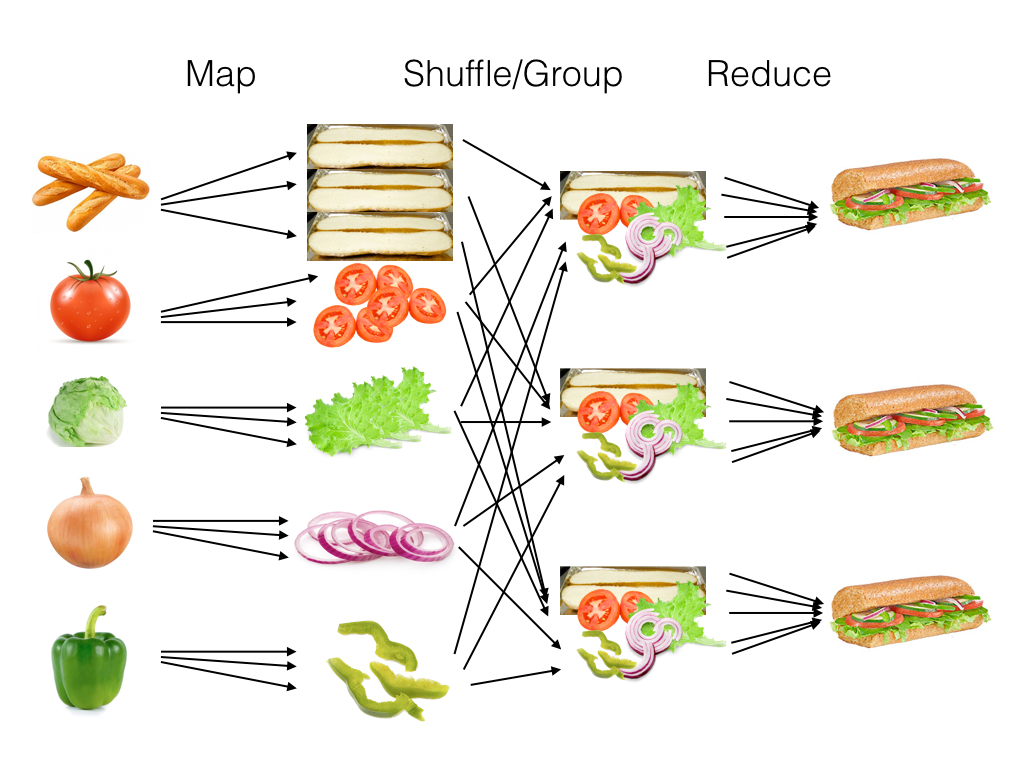
Typically, MapReduce‘s users will implement the map and reduce functions, and the framework will call them on a large cluster of machines.
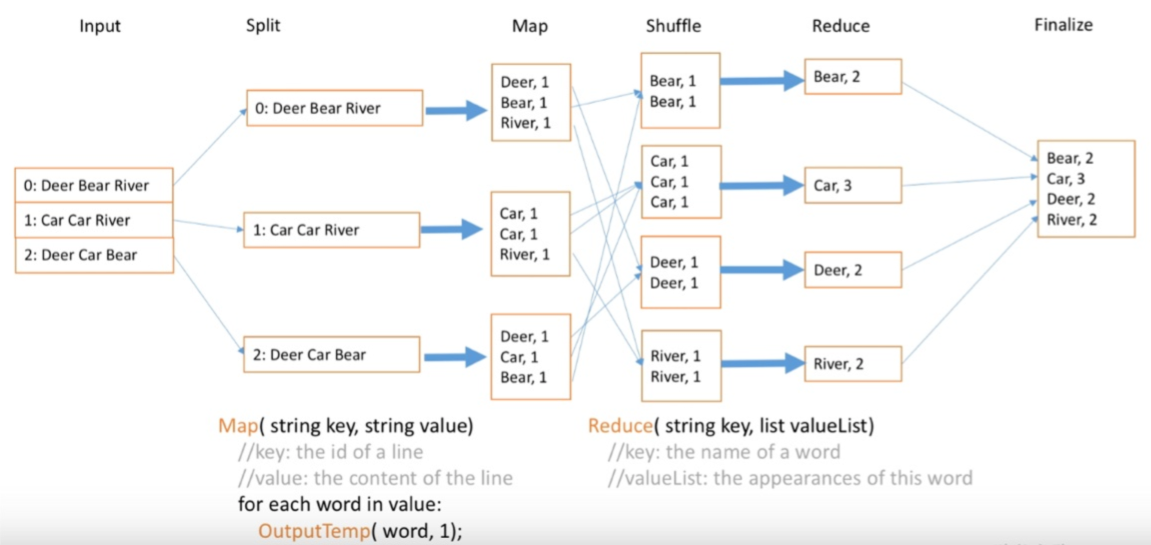
In practice, except for map and reduce, there are some other processing stages in the whole procedure, including Split, Combine, Shuffle, Sort, etc.
Suppose we want to count the numbers of each word from a big file, we split the file into 3 sub-files, then finish the word counting task in each server, then we use the words as keys for shuffling, and finally combine the results from the same key.
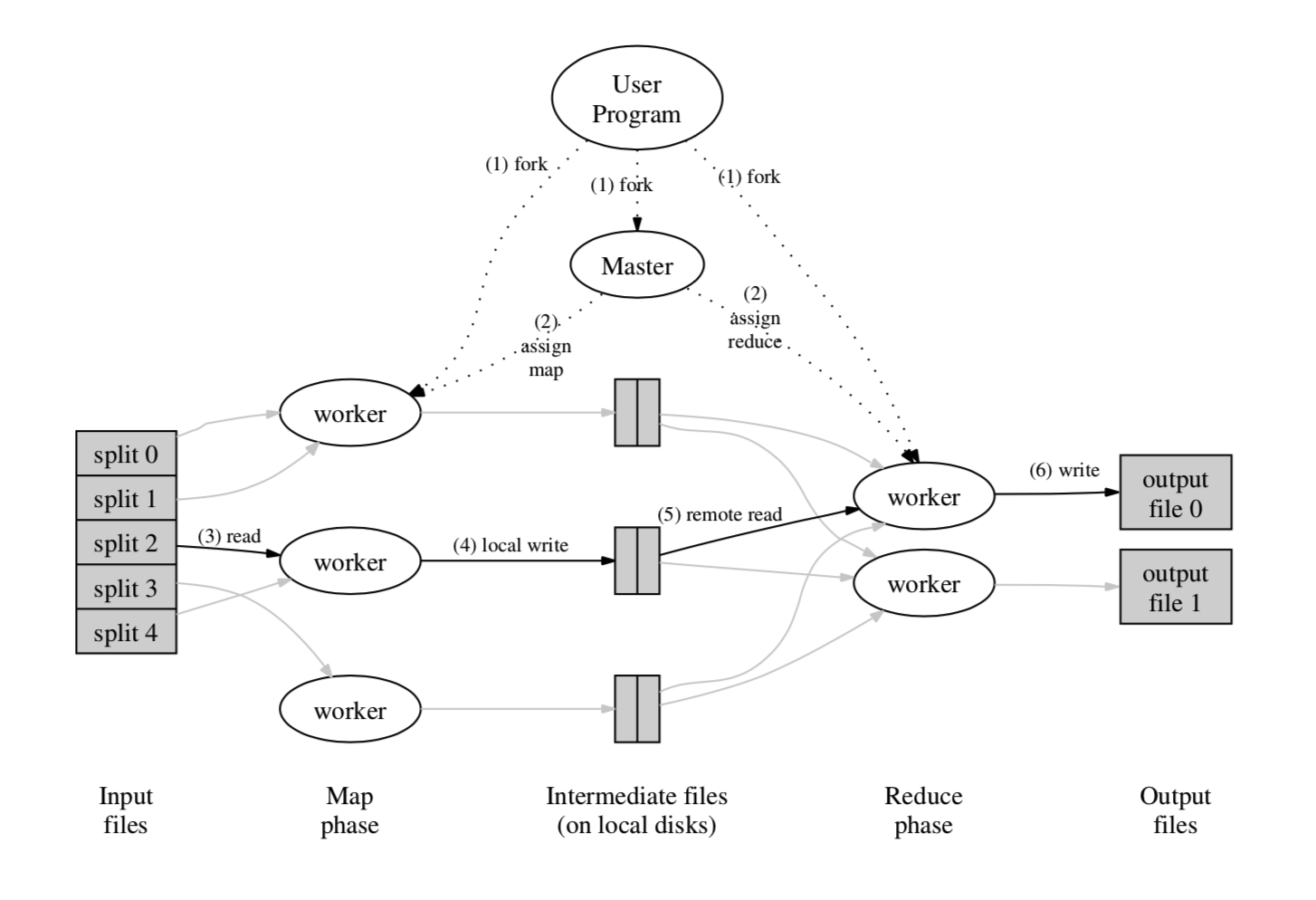
The framework will also support with redundancy and fault tolerance, since errors may happen on any server. In the original implementation of Google, they use the architecture of the master-worker pattern. The master node will assign jobs to workers and maintain their status.
The master pings every worker periodically. If no response is received from a worker in a certain amount of time, the master marks the worker as failed. Then reschedule the job for anther healthy worker.
Final thoughts
In recent years, Google has moved on to some other technologies which offer streaming data operation instead of batch processing, but there is still much existing software such as Hadoop use the MapReduce computing model.
The major contributions of MapReduce are a simple and powerful interface that enables automatic parallelization and distribution of large-scale computations.
Split-apply-combine is a general strategy in the world of distributed computing, MapReduce is a great example which confirms:
Technologies come and faded, but the principle tends to remain more constant.
References
Join my Email List for more insights, It's Free!😋