When I started to learn data structures many years ago, disjoint-set is the one that gave me a deep impression, it’s so simple, but elegant and useful.
In this post, we will learn how disjoint-set works, then we implement a maze generator with it. I wish this will help the beginners to find fun of data structures.
Disjoint Set (Union-Find) Data Structure
disjoint-set is a data structure that tracks a set of elements partitioned into a number of disjoint (non-overlapping) subsets. According to the definition, two disjoint sets are sets whose intersection is the empty set.
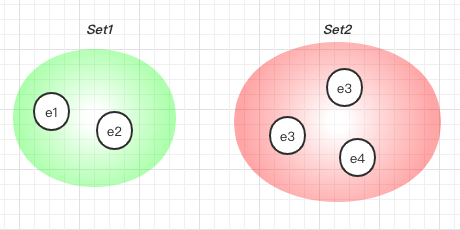
In above image: e1, e2 is in Set1 and e3, e4, e5 is in Set2.
There are two operations for a disjoint-set, union and find, this is the reason why disjoint-set also be called with the name union-find:
|
If we union any two elements from two different sets, then they will be merged into one larger set.
For example, if e2 and e3 are unioned, which also means e1 and e5 in the same set.
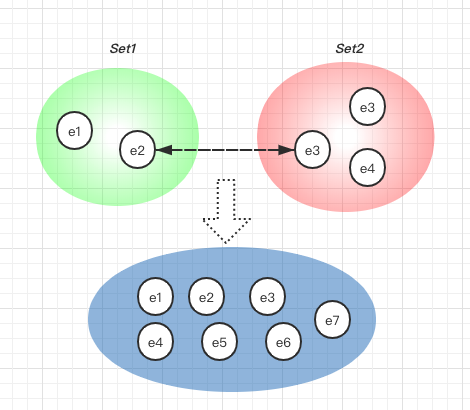
With the result of find, we can test whether two elements belong to the same set. If find(e1) equals find(e2), this means e1 and e2 are in the same set.
This is a useful property of disjoin-set, especially for graph algorithms, in which we need to test whether two nodes have connectivity with each other.
Given the above specs and descriptions, how to implement this data structure by yourself?
You can spend several minutes trying it out by your hand, this is a superior way to study data structures and algorithms.
Naive implementation with an array
Firstly, we need to find out use which basic data structure in programming languages to store data. If we could store the parent of one element, we could construct a tree-like structure to keep the relationship between elements.
Let’s take an example, if we finished operations of union(e1, e2), union(e2, e3), union(e3, e4), the constructed tree will be like this(suppose we always set the first parameter as a parent):
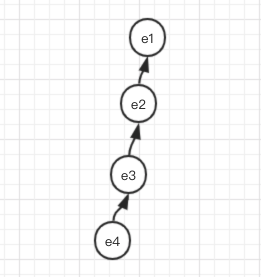
The function find(e) will be implemented in recursive style, try to find parents from bottom to top, according to the tree.
|
Ok, we finished the first version of union-find with array!
Let’s run more test cases for verifying the correctness of our implementation, what happened if we run operations of union(e1, e2), union(e3, e4), union(e2, e4) ?
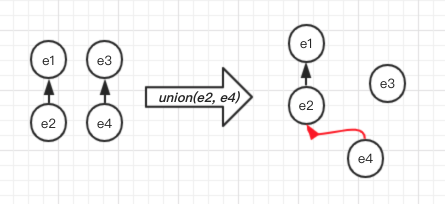
Wait! This is not what we expect! According to the definition above, we expect e1, e2, e3, e4 are in the same set. Seems we have a bug in the function of union_set.
Yes! What we want to do is union two sets, not just the parent relationship of two elements. When we union(e2, e4), we need to find the root of e2 and e4 and finish it with an operation of union(e1, e3).
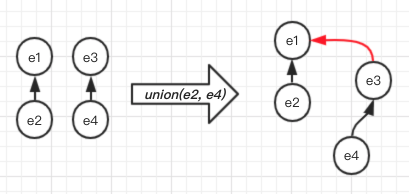
Let’s fix the bug in the first version:
|
Naive implementation’s time complexity is O(N).
#1 Optimization with Path Compression
Let’s try to make it faster. In the naive recursive function of find, if we cached the result in each recursive iteration, the time performance will be much better. This is the caching technique which explained in Caching: from bottom to top.
|
After a function call of find, we can make the tree much flatter(the depth is shorter, which speeding up future operations on these elements):
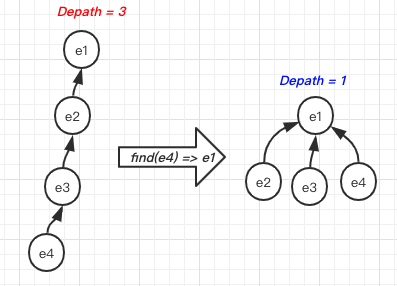
#2 Optimization with Union by Rank
In our first version of union_set, we always set e1’s root as the parent of e2, what will happen after multiple times of union operations?
The depth of the tree will keep growing. Can we do some optimizations for this? A strategy called union-by-rank will help with this.
If we use another array to record the rank(the depth of an element’s subtree), then we always try to set the element with larger depth as the parent.
|
Let’s take an example to understand this:
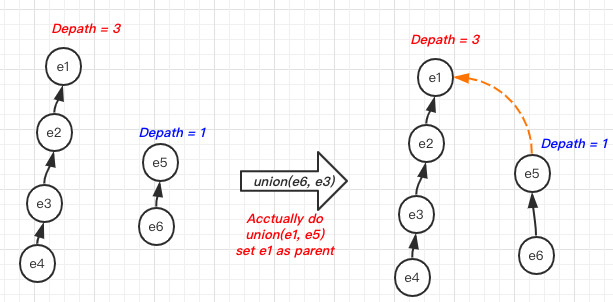
With the operation of union by rank, when the depth of two roots is not equal, we can keep the depth of tree not to grow!
There is another strategy called union by size, which always attaches the tree with fewer elements to the root of the tree with more elements.
The time analysis for the optimized version involves many mathematics tricks.
Let’s simply come out the conclusion, with path compression and union by rank, the amortized time complexity is only O(α(n)), where α(n) is the inverse Ackermann function, α(n) is less than 5 for any practical input size n.
It’s a really good time performance!
Random Maze Generation
Finishing a small project with the newly learned data structure will do much help for your learning.
When I read Algorithms by Robert Sedgewick, there was an exercise to generate a random maze with disjoin-set.
It’s a nifty algorithm, the simplified code like this:
|
We use disjoin-set to test whether start and goal have been connected with each other, randomly remove an edge in the map until they are connected.
A generated maze look like this, with start cell at left-up corner and goal at the right-bottom corner:

Reference
Join my Email List for more insights, It's Free!😋