Every programmer will encounter this computing concept: Caching.
It is a core and broad concept that every programmer should have a deep understanding of, it’s extremely important for system design and performance-critical programs.
There are only two hard things in Computer Science:
cache invalidation and naming things.
– Phil Karlton
Technologies come and faded, but the principle tends to remain more constant.
In the computing world, ubiquitous technologies originated from the concept of Caching. Caching is designed and implemented in multiple abstraction layers, ranging from CDN, web browser, operating system, CPU and algorithm design.

What’s Caching
cachingexplained.com will give you the best and lively explanation of Caching.
From Wikipedia: “A cache is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere.“
The essential idea of Caching is to use space for time optimization, it’s a trade-off between size and speed.
Caching is used in scenarios like:
Read operations outnumber write operation.
The operations go with the principle of locality.
The benefits of Caching include increasing read throughput and reducing the system load on the backend.
Here are some key aspects related to Caching:
The hit ratio
$$ \frac{ N(hit) } { N(hit) + N(mishit) } $$
A mis-hit means, the fetched content is not in Cache, and an additional request will be made to fetch it. Apparently, A higher hit rate means more efficiently the cache works.
The cache data accessing and updating strategy
There are multiple Caching Strategies, we should choose the suitable one according to the data access pattern, that is to say, how the data is read and written.
Furthermore, a usual cache is implemented with limited size. When the cache is full, we need to choose which cached content to be evicted (or replaced with new data), there are several normal strategies here:
Least recently used (LRU)
Least frequently used (LFU)
Most recently used (MRU)
First in, first out (FIFO)
Meanwhile, caching may introduce some other issues, such as data inconsistency.
Single or distributed caching.
Distributed caching is suitable for high traffic sites; it will be much more complicated in a distributed context.
Let’s discuss some classic usages of Caching.
CDN
CDN(Content Delivery Networking) is the crucial Internet infrastructure, implementing the concept of Caching.
CDN improves the loading time of web pages and speeds up on-demand video downloads and streaming. When we are streaming videos of Netflix, instead of fetching the video directly from the central server, the client downloads the video from the CDN node, which geographically closes to us, shortening the loading time.
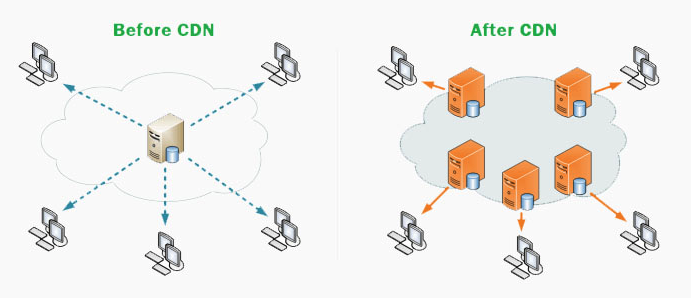
A typical CDN workflow is:
When the client requests data from the CDN node, the CDN node checks whether the cached data is out of date.
If the cached data has not expired, the cached data is directly returned to the client.
Otherwise, the CDN node sends a request to the Origin Server. Pull the latest data from the Origin Server, update the local cache, and then return the latest data to the client.
The trade-off here is how long will the CDN node cache content, which has a direct impact on the “hit ratio”.
If the CDN cache time is short, the data on the CDN edge node is most likely to be outdated, resulting in frequent requests to the Origin Server, which increases the system load of source servers and delays the user’s access. If CDN cache time is too long, expired data may be served to the client.
Follow up question: How a CDN server checks whether a client has the latest cached content?
The answer is referring to the HTTP caching methodology.
HTTP Caching
In the context of the Web, users read more frequently than write.
Fetching data over the network is both slow and expensive, thus the ability to cache and reuse previously fetched resources is critical for optimizing performance.
There are a bunch of cache schemas used in the context of HTTP. The most important cache header is cache-control.
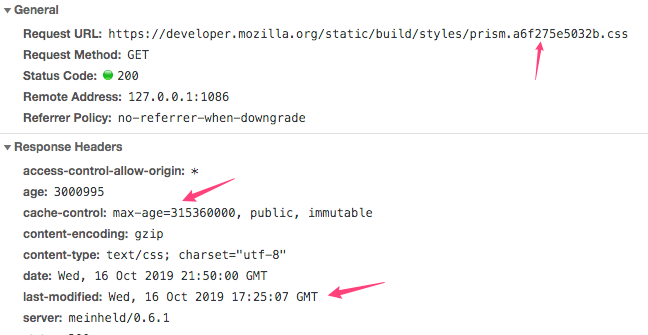
- Cache-Control: no-store The cache should not store anything about the client request or server response. A request is sent to the server and a full response is downloaded each and every time.
- Cache-Control: no-cache A cache will send the request to the origin server for validation before releasing a cached copy.
- Cache-Control: private “private” indicates that the response is intended for a single user only and must not be stored by a shared cache. A private browser cache may store the response in this case.
- Cache-Control: public The “public” directive indicates that the response may be cached by any cache. If content needs to be cached in CDN, “public” is required.
But how we resolve the stale data issue?
The answer is Etags/Last-Modified, the server will check these headers to determine whether the local cache of the client is validated.
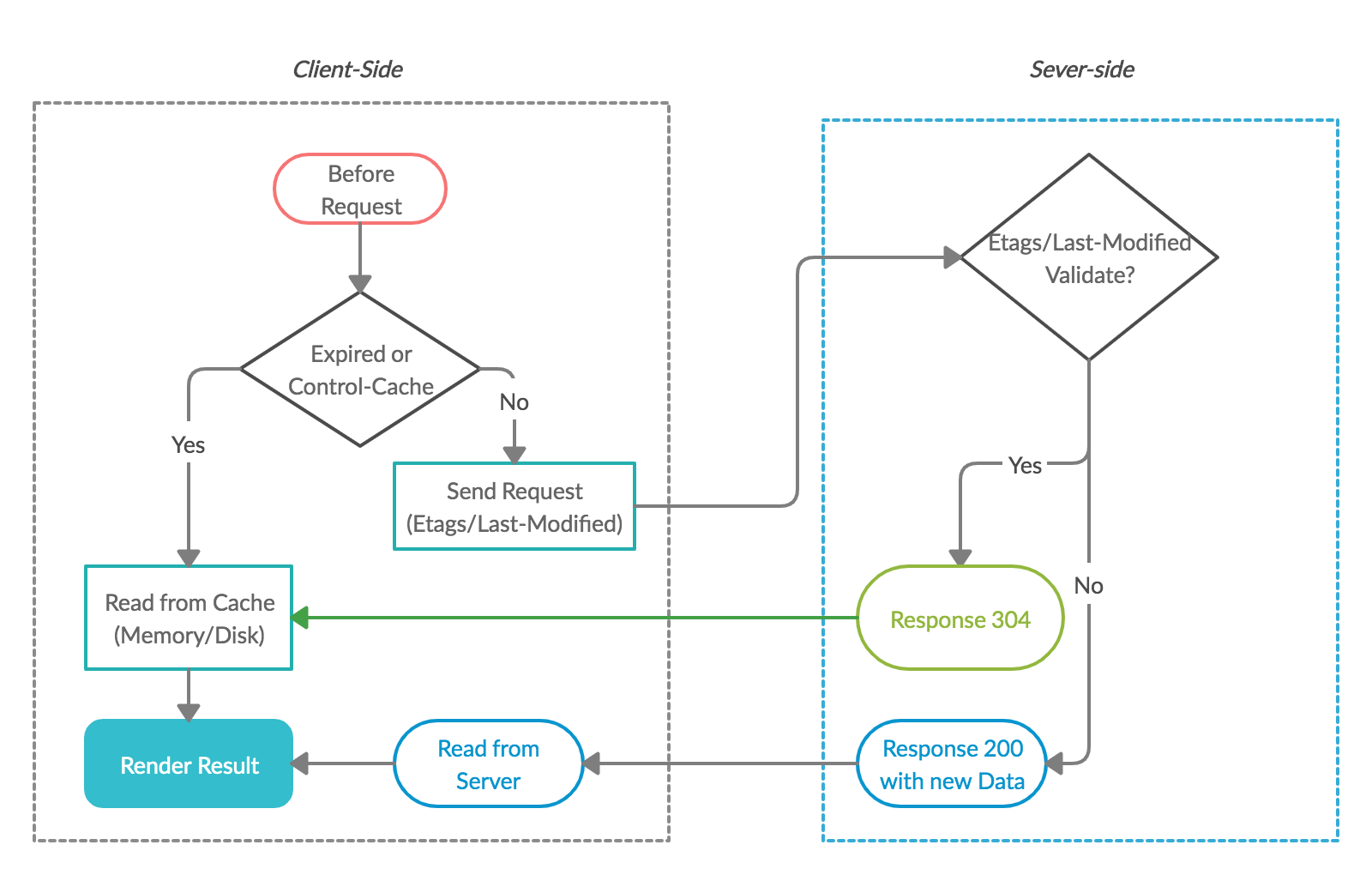
An HTTP response with 304 will be sent if it’s validated, otherwise response 200 with the newest content.
Another solution for expired data is generating a new unique URL for resources, in normal cases, the files of stylesheet files, images in HTML pages, Javascript files will embed a fingerprint in the filename. So that the clients will fetch from the new URL if the server updated content.
Combining the usages of cache-control, Etags, and unique URLs, we can achieve the best: long-lived expiration times, control over where the response can be cached, and on-demand updates.
Nginx Caching
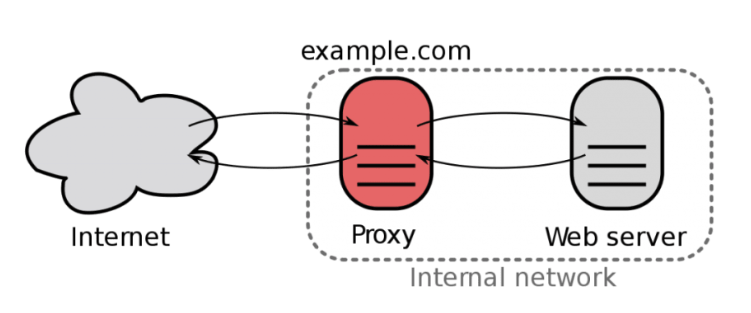
In practice, Nginx generally used as a reverse proxy or load balancer in front of applications, it can also act like a cache server. A simple configuration for Nginx caching is:
|
It’s a transparent cache layer for almost any backend application, which means concise architecture.
Another point that needs to be noticed here is that we set the size of memory space(for cache keys) to 10m, the cached value is stored in disk with path /tmp/nginx.
The option of inactive=60m used to specify how long an item can remain in the cache without being accessed.
Except for better performance, Nginx cache could also improve the availability of sites, we could use proxy_cache_use_stale options for delivering cached content when the origin is down.
Nginx has other rich features like traffic limiting, content compression, etc. If you are interested in high-performance tunning, I strongly recommend you to read: Nginx High-Performance Caching
Linux System Caching
Keep in mind, system-call is expensive and data operation on disk(read/write) is much slower than operation on memory. Linux will maximize the use of a computer’s memory for the best performance.
Let’s check command ‘free’:

As we can see, there is not much free memory. Even we did not run many applications currently.
Don’t worry, Linux is not eating your memory. The system is just borrowing unused memory for disk caching. This makes it looks like you are low on memory.
When data is written, Linux first writes it to a Page Cache (in memory) and mark the page to Dirty, the content of these dirty pages is periodically transferred (as well as with the system calls sync or fsync) to the underlying storage device.
Let’s run some commands to verify it:
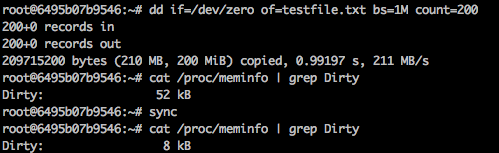
From the output, we could find out after a data writing of 200MB, the Dirty pages in the system grows.
Then if we run the command sync, it will shrink because data in Dirty pages have already synced into the disk.
File blocks are written to the Page Cache not just during writing, but also when reading files.
For instance, when you read a 100-megabyte file twice, once after the other, the second access will be quicker, because the file blocks come from the Page Cache in memory directly and do not have to be read from the hard disk again.
CPU Caching
CPU caching was invented to bridge the speed gap between the CPU and main memory.
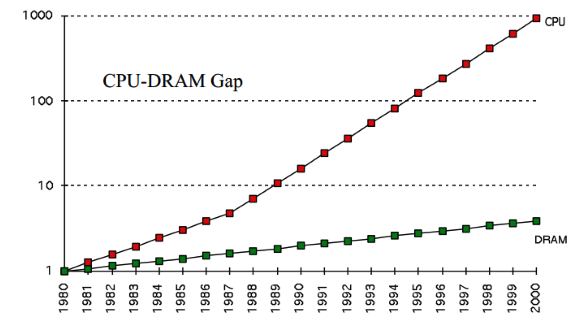
CPU caches are small pools of memory that store information the CPU is most likely to need next. All modern CPUs have multiple levels of CPU caches. Access times vary greatly between each Cache level, the faster level’s cost per byte is higher than slower one’s, also with smaller capacity. Cache L1 is faster than Cache L2, and Cache L2 is faster than RAM.
According to the principle of locality, most of the time spent by a program focuses on core operations, and CPU is likely to access the same set of memory locations repetitively over a short period of time.
It’s critical to follow this principle because a high mis-hit ratio on Cache could introduce a performance penalty on the program.
Let’s have a check with these two C functions, what are the differences between them?
Why the first function is almost 2 times faster than the latter one?
|
Because row-major layout in memory is used by C/C++ compilers, when the data in a[i][0] is accessed, the nearby data a[i][1] ~ a[i][K] will likely be loaded into to Cache.
According to the iteration order, because elements nearby have been cached, we will get a high hit ratio on the cache.
But if we reverse the iteration order into col-major, since the loaded data is not accessed afterward and most data is not fetched from cache, it will trigger a high mis-hit ratio issue and bad performance on running time.
Caching in Algorithms
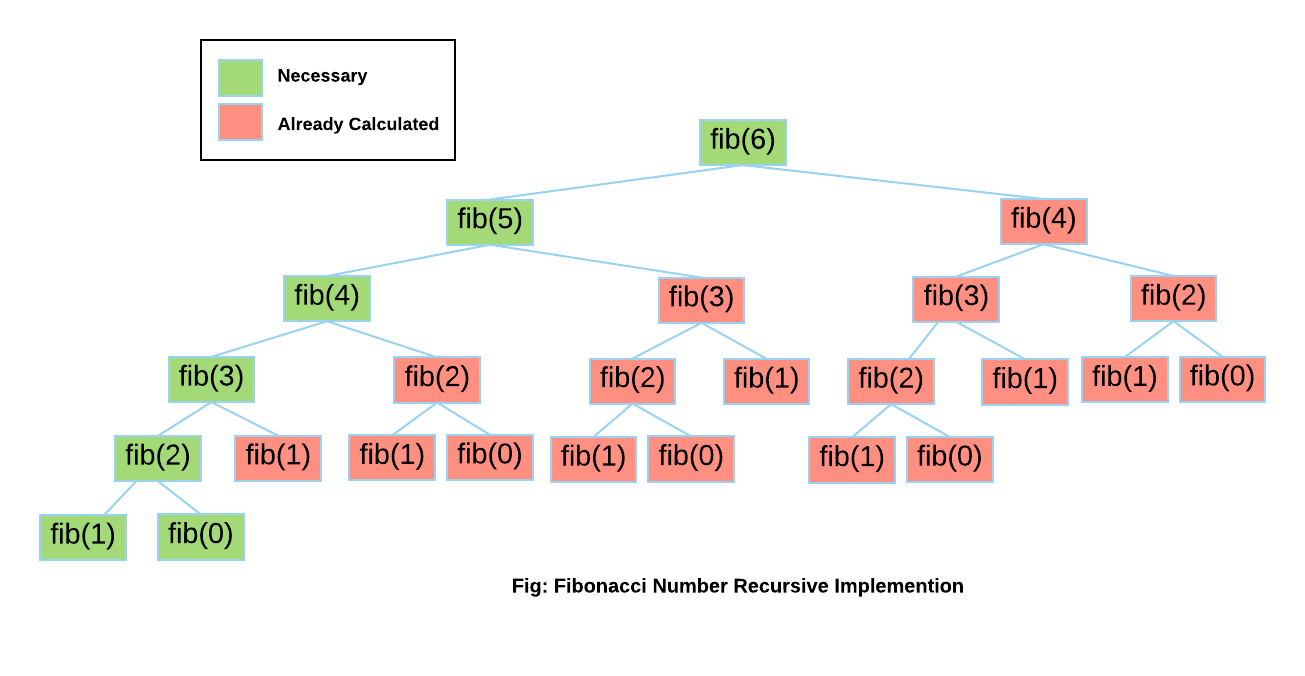
In algorithms design, we commonly store the computed result in a cache for time performance. Let’s have a dig on the classic recursive version of Fibonacci algorithm:
|
If we analyze the computing process in visualization, we will found out there are some duplicated parts during the computation. Its complexity in Big O notation is $O(2^n)$.
Memoization (top-down cache filling) can be used to optimizing the performance, we use an array to store the computed result:
|
Or we can use the bottom-top caching filling, which will produce an iterative version program:
|
The idea of reducing duplicated computing is also applied in Dynamic Programming(DP), the key observation for DP problem is finding the overlapping subproblems, and use cache to store overlapping results.
Summary up
We have a study on the Caching technique at different layers. Caching is not only a method for architecture and design, but it’s also a general idea for solving problems.
The essential principle is:
store duplicated data on a quicker component if needed(cases in CDN, Memory Cache)
use cache to reduce duplicate in computing(case in Fibonacci/DP).

In most cases, Cache is the abstraction layer we needed when solving performance problems and Caching techniques deserves serious study for an aspiring programmer.
References
- CDN: https://www.globaldots.com
- CDN-Caching: https://support.stackpath.com
- HTTP Caching[1]: https://tools.ietf.org
- HTTP Caching[2]: https://developer.mozilla.org
- Nginx Caching: https://docs.nginx.com
- CPU Caching: https://www.extremetech.com
Join my Email List for more insights, It's Free!😋